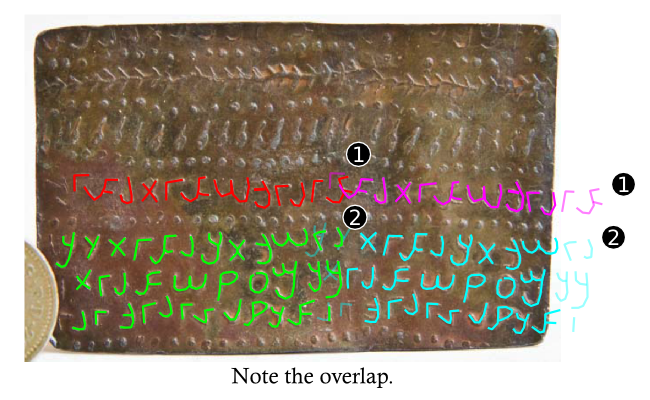
So, you’ve likely noticed that this website has been quiet for a while with not much happening here, and that subscriptions have been disabled. A lot has happened in the 15 some-odd years that I’ve been blogging about the Aramaic language, and a lot has changed as well.
The main reasons for much of that change are simply a matter of where I am in life right now. Translating was, at one point, my full-time endeavor, and my sole academic focus. But since then I’ve landed a tenured position at a local college and am the head of my own program with my own students and they have had to take priority.
Additional matters of focus in life are upon my family and our health. During the ongoing pandemic, our household caught Covid twice. Some of the residual effects of it still haven’t left us. To this day, I am continuing to deal with occasional bouts of neuropathy and some memory problems. In an effort to help mitigate them, we’ve focused inwards for a bit and we’ve begun a number of projects, including major renovations to our home, gardening, and animal husbandry to help us weather this thing. As it can be imagined, these also take a significant amount of our time and attention, too.
Finally, one of the peripheral reasons that has also been of influence to my involvement is a matter of the kind of people that my work has attracted. Let me be clear: The vast majority of folk have been respectful of the language and its historical context, and academic in their pursuit of it. However, a consistent contingent of enthusiasts have been interested in it solely to promote various kinds of charlatanism, and that has been incredibly difficult (emotionally and practically) to deal with.
Here are but a few examples:
- I have had many students and customers take the knowledge of Galilean Aramaic I had freely shared with them to promote websites and churches or other organizations that implied that without this “secret knowledge” of the “true words” of Jesus that they were at some kind of theological disadvantage, even to damnation.
- I have had a “messianic yeshiva” claim that I was a “visiting professor” and use my name and face to endorse their website without my knowledge or consent.
- I have had a customer use a translation I had given them to deceive other people to believe that they could speak in tongues.
- I have had another student take a translation I had given them to deceive other people to believe that they were possessed by a demon.
And these are only some of the things that I am willing to share. If any of these were untrue, I would not have listed them, and some of these – as you can plainly see – are extreme and even damaging.
So, with all of this in mind, I do not have the ability to keep on top this site and what it entails in addition to my current set of responsibilities – there are simply not enough hours in the day. That said, I have no intentions of taking AramaicNT.org or its content down, but in the next few months I may convert it to a flat-file site away from WordPress for archival purposes and make the subscription content freely available. (No guarantees as to when.)
And this leaves one last thing: At one point I had planned on publishing my grammar of Galilean here – but because of everything above (both the crazy and the practical) – it has been permanently put on the back burner. Right now I am uncertain as to where it will land. It is not in a state that I could readily release, but perhaps one day in the future I could put it up on a GitHub repository for folks to make use of and submit additions. Once the site is archived, I may have more information in that direction as well.
In the meantime, stay well, and we’ll see what the future brings. 🙂
Peace,
-S