Happy New Year!
I was hoping to have this ready-to-release today, but instead I’d rather share what I have already competed, and solicit feedback to make it even better:
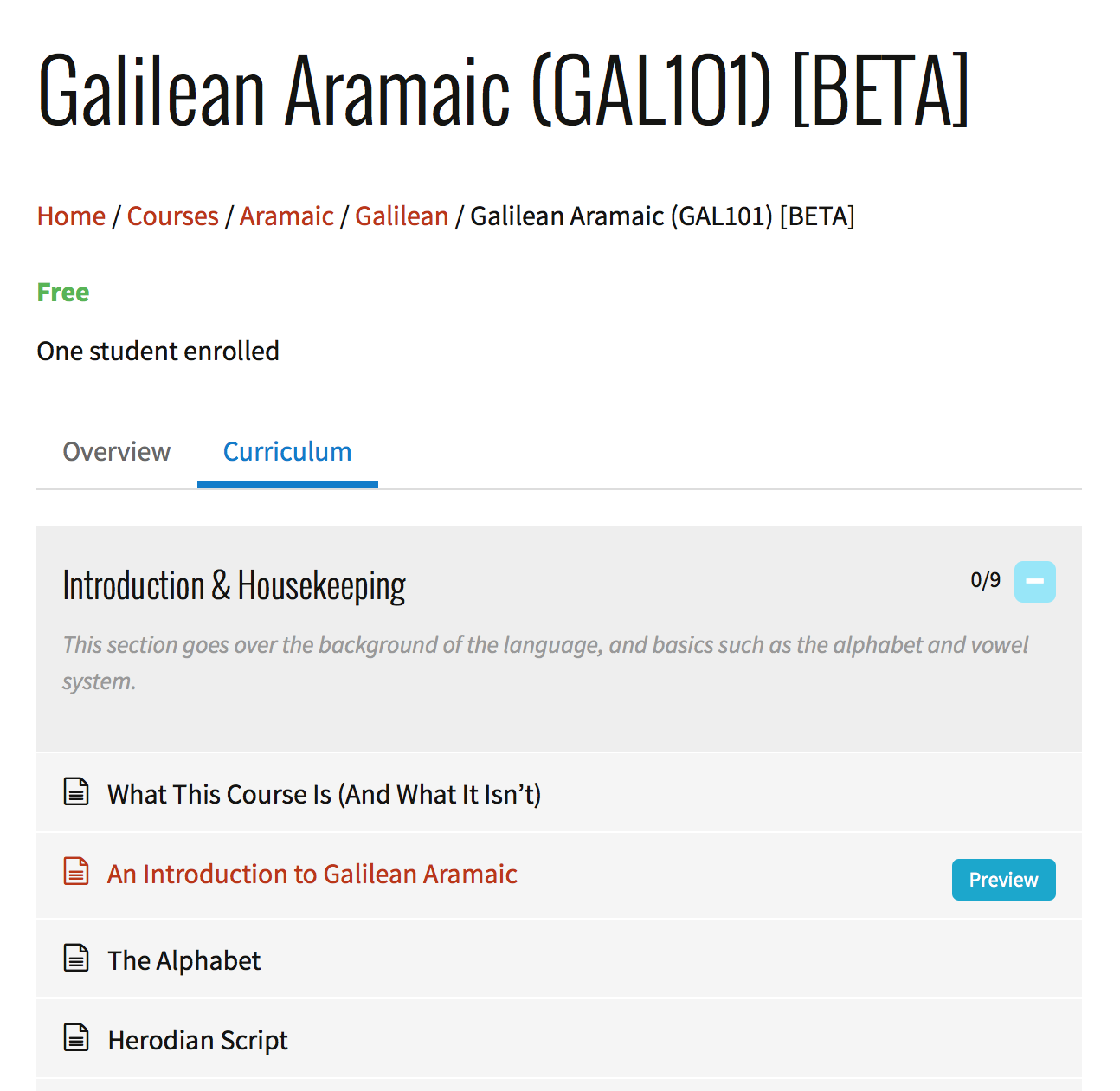
I’ve been working on a brand new Galilean Aramaic 101 course. 🙂
Using the LearnPress plugin, I’ve been able to more rapidly work on a bunch of stuff that was slow and difficult to handle before (when it came to making supporting multimedia, editing, or coding, coding, coding… it was off-putting). Now if I have an idea for a new lesson, I can put it together in a matter of hours instead of weeks, or if I have an idea for a new course, I can put it together in a matter of days, rather than months.
Right now it’s in BETA. That means it’s not complete, but it’s well on its way there, and that I also need your feedback to make it better. Visit the course page, sign up, try out the lessons and quizzes, and leave comments on the courseware.
Other courses I’m currently working on outlines for are the second level of this course (which will be more comprehensive), a re-do of the Lord’s Prayer course, and a course on the Sermon on the Mount. Once the Beta period is over for 101, we’ll see what direction these will go. 🙂
Peace,
-Steve