(See Digital, Interactive, and Topical Galilean Aramaic Dictionary for the background to this post.)
So how can I get this off the ground?
Figuring out how to tackle this project proved an interesting series of events. When making a general, practical dictionary for people to learn important words, the first question was, “What words does one choose?” The obvious answer seemed to be, “The words that are of the highest frequency in the corpus.” These would be the words that a student would come across the most, and therefore be of most immediate use.
So a few years back I collated the Concordance listings on the Comprehensive Aramaic Lexicon for all of the texts listed in the Palestinian Aramaic corpus.
The Concordance mode merely scans over the requested lemma file (the way that the CAL internally represents documents with lexical tagging), tallies up each instance of the word, and then sorts them in alphabetical order. If one simply collates each of these generated concordances (some 30 or so documents for JPA) and sorts them by frequency, you’re left with a list of nearly 9,400 words for the corpus in order of “popularity.” (I’ll probably post the full frequency list on the dictionary website later.)
Thousands of words are great for print dictionaries, but for a visual dictionary, it was a bit much. The distribution was also extremely skew (as it is for virtually all languages) with many words up front having huge attestation, trailing off into a very long tail of rarely used words, finally ending with a long line of singletons.
| Attestation: | TOTAL Number: |
|---|---|
| ≥1000 | 65 |
| ≥100 and <1000 | 469 |
| ≥10 and <100 | 1960 |
| =1 | 3229 |
N = 9379
As such, the list needed to be pruned back a bit. I decided to adopt the following two criteria:
- The first set of words must be nouns. (This is a visual dictionary, and nouns are easier to illustrate. All verbs, adverbs, prepositions, etc. were tossed from the list.)
- An individual word needs to appear at least 5 times in the corpus. (This cut off the aforementioned long tail of some 5784 sparsely attested words.)
Between those two criteria, it brought the list from many thousands of words, down to a “mere” 1,700. This was still a bit much for the initial dictionary in the amount of time I have to complete it.
Additionally, among those ~1,700 words, a large number of them were still tricky to illustrate because they were:
- Abstract (like “knowledge” or “name” or “obligation”), or
- Religious jargon (like “Mishnah” or “Torah” etc.), or
- Otherwise better suited to a separate unit or set in context with its other members (numbers, family, etc.)
A single image slide could not provide sufficient context for these words, so pulling them all out, I was left with a list of about 600 “easily illustratable” words.
This is doable!
The Next Steps:
The List
My next step from here is going to be formatting this list in a readable form for the project’s website. When I start implementing the dataset, this will serve as the “checklist” towards completion and also aid with any crowd sourcing efforts.
Each word needs to have its gloss and orthography checked against the Galilean corpus (sometimes lemma forms diverge, since most lemmas are based off of Eastern Aramaic forms – I’ll put together a list of links), and be broken down into syllable and letter chunks:
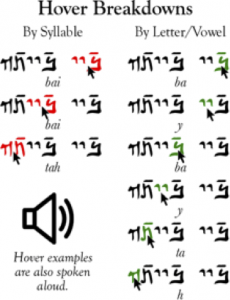
Each word also needs to have its audio recorded.
Once the list is posted, I’ll be sending out a request for help finding images. The images need to be public domain, or otherwise have their copyright released in such a way that they can be used for educational purposes. When this project is done, I’m going to make the source code available for other educators so that they can build their own datasets for different languages, and I want the images to be part of that.
The Test Set
While the full list percolates, I’ll need to compile a small subset of the list – perhaps just a few dozen words – to be the test set. This is what I will use to check to see how the audio will work and to later use as a “dummy” set to implement the interface.
The Audio Chunks
This is going to be, perhaps, the most difficult part.
I’ll need to compile a list of all possible single letter-vowel and syllable combinations and record audio for each one, and then develop some schema to store them so that the software can make use of them.
Luckily, due to the restricted vowel inventory of Galilean, this is a much more attainable task than if it were another dialect. For letter-vowel pairs, it’s roughly 120 combinations (and since that’s doable, that’s where I’ll start). With full syllables, however, I may be looking at 2,500 possible combinations total. Ugh… First things first, though.
The Interface

Finally, with the test set in hand, I’ll start working on the actual code driving the visual interface based off of the initial mockups. This, I anticipate, is going to be one of the easier and fun bits to get done, but when I do sit down to it I’m going to post another update about the design process.
User Testing
This is where everyone else comes in. Once I have a prototype up and running, I need you – yes YOU, reader on the Internet – to help me test it, break it, and reform it stronger. With every successive wave of testing, it will become a better tool.
Wish me luck. 🙂
Peace,
-Steve